"twenty or thirty pages of ideas and information would be capable of turning the present-day world upside down, or even destroying it."
- New Concept English
互联(但似乎不互通)网上的今天,居然有人公开征集最危险的想法,让我不由得想到新概念英语上的这句话(,进入教材是使文章广泛流传和长久保存的一个好方法,至少我搜的新概念教材占据了搜索结果的主要部分)。
而这些想法或深刻,或扯淡,或出自名人之口,或源于学术大家,我辈浅薄不可穷尽,亦无深入之志与力。不过随手翻看,倒是可以看到其中不乏优美的散文。其内容兼与《银河系漫游(搭便车)指南》媲美,许多都是关于宇宙、生命和一切一切的终极问题(The Ultimate Question Of Life, the Universe and Everything),使人怀念起庄子和屈原的精神!
于是,我不禁也要扯淡:(我不知道是否与他人看法接近,因我无暇,亦无兴趣作全面调查,所以,如有雷同,纯属巧合,算你倒霉,概不负责!)
地球上的生命,从简单到复杂,从低等到高等,从水生到陆生,从弱智到聪明,林林总总,纷繁芜杂,乃至西元二十有一世纪,有灵长类智人属之动物,发展出惊世骇俗之资讯(挨踢)科技及生物技术,更有将此二者截而合之之势。长此以往,必将开发以生物基因组作为储存咨询之技术,届时,必将出现极为人造之(微)生物(不同于现世之基因修饰生物,基因组之绝大部分皆人为设计,繁殖力强,承载信息量甚巨,不受芯片之2D尺度之限制),而彼时一旦人为(微)生物突变,人类灭绝,则地球之上,必起新一轮进化之狂潮。待其演进智慧,认识自我,必提出“何所从来?何其将往?”之冗杂问题,岂不无聊?
星期五, 一月 06, 2006
文化常识:往生咒
笨狸的blog上面提到了这个词汇,我很不幸的气到了他。故而,补充一下佛学常识,以备不时之(吹)嘘:
《往生咒》全名為《拔一切業障根本得生淨土神咒》,因而讓人誤以為此咒只適用於與往生有關的場合。 事實上,《往生咒》是《拔一切業障根本得生淨土神咒》的通行名稱,此咒包含現世及來生的雙重利益,為《阿彌陀佛根本咒》。與「阿彌陀佛」有關的二十多個咒 語中,此咒為最早出現的咒語。任何與「阿隬陀佛」有關的修持,都非常適用。
拔一切業障根本得生淨土陀羅尼,是出於《小無量壽經》(劉宋天竺三藏求那跋陀羅譯)與《佛說阿彌陀佛根本秘密神咒經》(曹魏三藏菩提流支譯)。它完整的名稱是:《拔一切業障根本得生淨土陀羅尼》,又名《阿彌陀佛根本秘密神咒》,通常稱為《往生咒》。
隋朝流傳下來的《阿彌陀經不思議神力傳》中記述了持咒的方法和利益:「如果我們要持誦往生咒,應該清淨三業,沐浴,漱口,至誠一心,在佛前燃香,長跪合掌,日夜各誦念二十一遍,就可以消滅四種嚴重的罪過(殺人、偷盜、邪淫、大妄語)、五逆罪(殺父、殺母、殺阿羅漢、出佛身血、破和合僧)、十種惡業(殺生、偷盜、邪淫、妄語、惡口、兩舌、綺語、貪愛、憎恨、愚癡),甚至連毀謗大乘經典的罪業,都能夠消除。現世一切所求,都能如意獲得,不被邪惡的鬼神所迷惑和擾亂。如果有恆心地持誦了二十萬遍,就會萌生智慧的苗芽。如果念了三十萬遍,就能親自看見阿彌陀佛。」
現在流行的往生咒,一般稱為《往生淨土神咒》,共有五十九個字,一共有十四句,也有說是分為十五句的。
《往生咒》全名為《拔一切業障根本得生淨土神咒》,因而讓人誤以為此咒只適用於與往生有關的場合。 事實上,《往生咒》是《拔一切業障根本得生淨土神咒》的通行名稱,此咒包含現世及來生的雙重利益,為《阿彌陀佛根本咒》。與「阿彌陀佛」有關的二十多個咒 語中,此咒為最早出現的咒語。任何與「阿隬陀佛」有關的修持,都非常適用。
拔一切業障根本得生淨土陀羅尼,是出於《小無量壽經》(劉宋天竺三藏求那跋陀羅譯)與《佛說阿彌陀佛根本秘密神咒經》(曹魏三藏菩提流支譯)。它完整的名稱是:《拔一切業障根本得生淨土陀羅尼》,又名《阿彌陀佛根本秘密神咒》,通常稱為《往生咒》。
隋朝流傳下來的《阿彌陀經不思議神力傳》中記述了持咒的方法和利益:「如果我們要持誦往生咒,應該清淨三業,沐浴,漱口,至誠一心,在佛前燃香,長跪合掌,日夜各誦念二十一遍,就可以消滅四種嚴重的罪過(殺人、偷盜、邪淫、大妄語)、五逆罪(殺父、殺母、殺阿羅漢、出佛身血、破和合僧)、十種惡業(殺生、偷盜、邪淫、妄語、惡口、兩舌、綺語、貪愛、憎恨、愚癡),甚至連毀謗大乘經典的罪業,都能夠消除。現世一切所求,都能如意獲得,不被邪惡的鬼神所迷惑和擾亂。如果有恆心地持誦了二十萬遍,就會萌生智慧的苗芽。如果念了三十萬遍,就能親自看見阿彌陀佛。」
現在流行的往生咒,一般稱為《往生淨土神咒》,共有五十九個字,一共有十四句,也有說是分為十五句的。
星期二, 一月 03, 2006
live.com可以注册?
貌似现在可以通过注册passport登录live.com?
反正live.com可以用我的hotmail登录了, 虽然邮件列表里还有gb2312的乱码,
点击邮件依然出现msn hotmail。
似乎这还是那回250MB邮箱的翻版,我没有进行个人信息的修改就可以使用live,大概是因为个人信息从那回就没改回来!而且我怀疑只要有个.net passport就可以!
这是否标志着MS真正部署了AJAX呢?
反正live.com可以用我的hotmail登录了, 虽然邮件列表里还有gb2312的乱码,
点击邮件依然出现msn hotmail。
似乎这还是那回250MB邮箱的翻版,我没有进行个人信息的修改就可以使用live,大概是因为个人信息从那回就没改回来!而且我怀疑只要有个.net passport就可以!
这是否标志着MS真正部署了AJAX呢?
最早的bioperl
根据http://bio.perl.org/DIST/,最早的bioperl 归档文件是v0.0.1,时间上溯到1998年。但bioperl最早的开发并非始于1998年,而是1995年。
v0.0.1是第一个cvs版本,其中,包含Bio::Parse, Bio::Seq, Bio::SimpleAlign, Bio::Tools等若干程序包。而Seq.pm中对于cvs之前的版本有着如下描述:
### Seq.pm
###
### $Id: Seq.pm,v 1.11 1998/11/02 16:03:34 dag Exp $
###
###
### MODIFICATIONS
###
### Prior to using a central CVS system on bio.perl.org:
### ++++++++++++++++++++++++++++++++++++++++++++++++++++
###
### VERSION 0.050, 3 Sep 1998:
###
### -- Added start() and end() and deprecated numbering().
### (Changes made by Ewan Birney).
### Converted all calls to numbering() to start().
### -- Officially graduated to Seq.pm.
###
### VERSION 0.047, 15 Jul 1998:
###
### -- Bug fixed in str() that caused failure in bounds checking if
### start does not begin with 1 (suggested by Tim Dudgeon)
###
### VERSION 0.046, 10 June 1998:
###
### -- Added & improved documentation, including internal hyperlinks, for
### generating docs using pod2html in the Perl 5.004 release.
### -- Not autoloading commonly used/small parsing and outputting
### methods (parse_raw, parse_fasta, parse_gcg, out_raw, out_fasta).
###
### VERSION 0.045, 5 June 1998:
###
.
.
.
.
而版权声明则始于1996:
# Copyright (c) 1996 Georg Fuellen, Richard Resnick, Steven E. Brenner,
# Chris Dagdigian, Steve Chervitz, Ewan Birney and others. All Rights Reserved.
# This module is free software; you can redistribute it and/or modify
# it under the same terms as Perl itself.
此外,在google上不完全搜索到的最早的rpm是perl-bioperl-0.04.3-8.i386.rpm。
0.0.1版的bioperl已经可以支持N多种文件格式,并且进行BLAST(包括web blast, local blast)等工作。而Bio::Tools::RestrictionEnzyme.pm还只能进行很简单的作业。
一切都刚刚开始。
v0.0.1是第一个cvs版本,其中,包含Bio::Parse, Bio::Seq, Bio::SimpleAlign, Bio::Tools等若干程序包。而Seq.pm中对于cvs之前的版本有着如下描述:
### Seq.pm
###
### $Id: Seq.pm,v 1.11 1998/11/02 16:03:34 dag Exp $
###
###
### MODIFICATIONS
###
### Prior to using a central CVS system on bio.perl.org:
### ++++++++++++++++++++++++++++++++++++++++++++++++++++
###
### VERSION 0.050, 3 Sep 1998:
###
### -- Added start() and end() and deprecated numbering().
### (Changes made by Ewan Birney).
### Converted all calls to numbering() to start().
### -- Officially graduated to Seq.pm.
###
### VERSION 0.047, 15 Jul 1998:
###
### -- Bug fixed in str() that caused failure in bounds checking if
### start does not begin with 1 (suggested by Tim Dudgeon)
###
### VERSION 0.046, 10 June 1998:
###
### -- Added & improved documentation, including internal hyperlinks, for
### generating docs using pod2html in the Perl 5.004 release.
### -- Not autoloading commonly used/small parsing and outputting
### methods (parse_raw, parse_fasta, parse_gcg, out_raw, out_fasta).
###
### VERSION 0.045, 5 June 1998:
###
.
.
.
.
而版权声明则始于1996:
# Copyright (c) 1996 Georg Fuellen, Richard Resnick, Steven E. Brenner,
# Chris Dagdigian, Steve Chervitz, Ewan Birney and others. All Rights Reserved.
# This module is free software; you can redistribute it and/or modify
# it under the same terms as Perl itself.
此外,在google上不完全搜索到的最早的rpm是perl-bioperl-0.04.3-8.i386.rpm。
0.0.1版的bioperl已经可以支持N多种文件格式,并且进行BLAST(包括web blast, local blast)等工作。而Bio::Tools::RestrictionEnzyme.pm还只能进行很简单的作业。
一切都刚刚开始。
星期一, 一月 02, 2006

需要与keso的screenshot商榷的
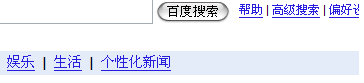
keso在donews上贴了个帖子抱怨两个忌讳的字眼,其实,事情是这样的(我也贴图说话,“沒圖沒真相”!):
baidu如是:
yahoo亦复如是:
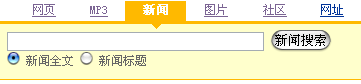
keso光顾着看图了,忽略了比图像更重要的是文字!
yahoo亦复如是:
星期日, 一月 01, 2006
GoPubMed: 用GeneOntology 探索PubMed
刚刚察看了Slashdot.org的RSS,看到一条消息,引用了这篇文章。这是Gene Ontology在PubMed这样的超大型数据库上的一次伟大尝试!直观的来看,一旦这个项目完成,对于跨领域、跨学科的研究工作者来说,他们将很可能不必再费尽心力研究另一个领域中的陌生术语,而是得到一个智能的百科全书,而且机器尽量消除了不同术语之间的歧义和重复,使得语义和实体得到了对应。
全文发表在Nucleic Acids Research上。
对于Gene Ontology的概念和简述,可以参见《什么是Gene Ontology?》和网络上GO的定义。
PubMed:
PUBMED是美国国立卫生研究所(NIH)下属美国国立医学图书馆(NLM)开发的因特网检索系统,建立在国立生物医学信息中心(NCBI)平台上。 PUBMED主要提供基于WEB的MEDLINE数据库检索服务,其中包括医学文献的定购、全文在线阅读的链接、专家信息的查询、期刊检索以及相关书籍的 链接等。
全文发表在Nucleic Acids Research上。
对于Gene Ontology的概念和简述,可以参见《什么是Gene Ontology?》和网络上GO的定义。
PubMed:
PUBMED是美国国立卫生研究所(NIH)下属美国国立医学图书馆(NLM)开发的因特网检索系统,建立在国立生物医学信息中心(NCBI)平台上。 PUBMED主要提供基于WEB的MEDLINE数据库检索服务,其中包括医学文献的定购、全文在线阅读的链接、专家信息的查询、期刊检索以及相关书籍的 链接等。
订阅:
博文 (Atom)
